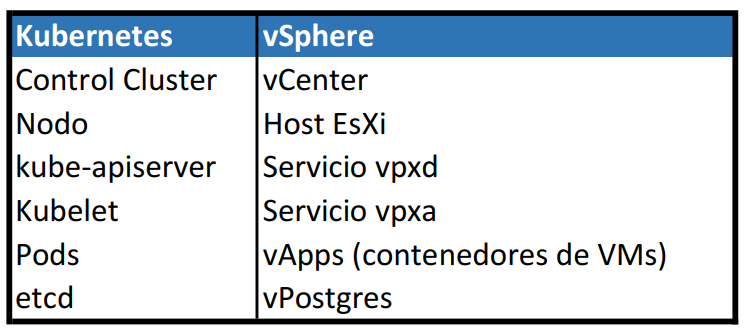
A fines de 2018 me tocó ser parte de un proyecto que requería que aprenda y certifique toda la suite de NSX, en Enero de 2019 terminé de certificar el examen VMware Certified Advanced Professional – Network Virtualization 6 (Deploy) y pude trabajar con eso por algunos meses.
Entre abril de 2019 y mayo de 2020 estuve alejado de NSX por motivos laborales, durante ese año VMware decidió discontinuar la versión del producto que yo conozco (NSX-V) y darle foco a NSX-T, acompañando su visión Any App, Any Device, Any Cloud.
Para no quedarme atrás estuve investigando, y algo que me sirve a mi es hacer paralelismos con lo que entiendo.
En algunas líneas quiero compartir cuales son las diferencias entre NSX-V y NSX-T para que puedas “pasar tu conocimiento” haciendo algunas equivalencias y/o diferencias.
Arquitectura
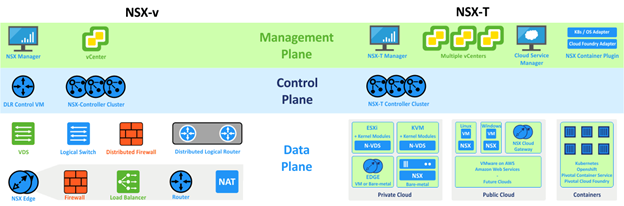
Al igual que en NSX-V, NSX-T Cuenta con 3 planos (Management, Control, y Datos) pero en esta nueva versión hay algunas diferencias.
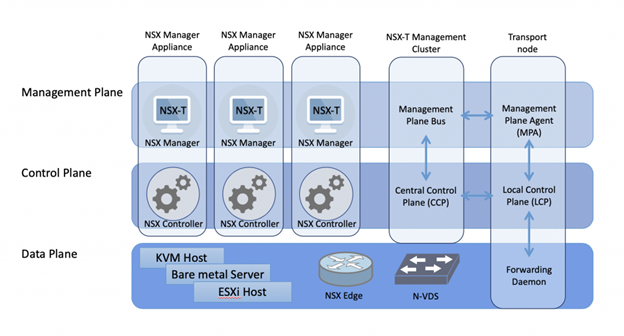
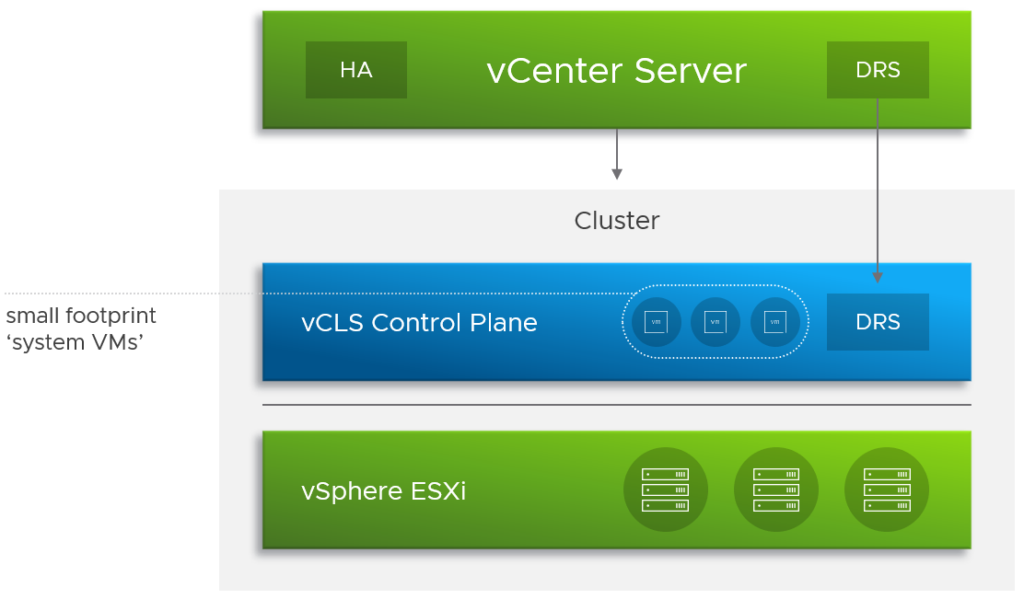
Management Plane
El Management Plane es el encargado de la administración de NSX. En NSX-V era un solo appliance (OVF) que después se registraba contra vCenter y hacia el deploy del control plane y preparaba los hosts, manteniendo un mapeo 1 a 1 entre el vCenter y el NSX Manager.
El deploy de NSX-T comienza del mismo modo (instalando un appliance) pero no requiere un vCenter para funcionar.
Adicionalmente ahora el NSX Manager está distribuido en un cluster de 3 virtual machines.
En la tabla a continuación podemos ver algunas diferencias entre ambos productos:

Sin embargo, el NSX Manager (Cluster) sigue siendo responsable de preparar hosts, crear nuevos logical switches, crear VMs de NSX Edge, al igual que proveer la API y la línea de comandos centralizada.
Control Plane:
La mayor diferencia entre NSX-V y NSX-T en relación al plano de control es el hecho de que ahora corre en las mismas máquinas que el management Management Plane.
Adicionalmente al no existir el concepto de Distributed Logical Router, la máquina de control del DLR no es necesaria.

Plano de datos – Encapsulación y Switching:
La mayor diferencia entre NSX for vSphere y NSX Transformers a nivel encapsulación dejamos de usar el protocolo VXLAN y pasamos a usar el protocolo GENEVE.
Adicionalmente, NSX-V requeria MTU 1600 para funcionar y ahora requiere 1700.
A continuación dejo algunos detalles extra:
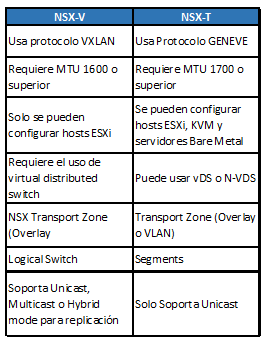
Respecto a los distributed switches, para NSX-T solo en entornos VMware se recomienda usar vSphere vDS, si vamos a usar KVM estamos limitados a usar N-VDS.
Plano de datos – L2 Bridging:
Una vez más, al no existir la VM del DLR, el Bridging se modifica y se crean los bridge nodes (dentro del kernel para los hipervisores).
Adicionalmente podemos crear bridge clusters para proveer redundancia.

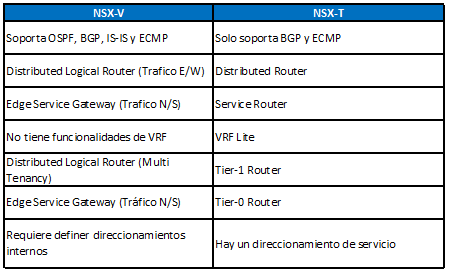
Plano de datos – Routing:
Estas son algunas de las diferencias entre NSX-V y NSX-T a nivel routeo.
Esto me costó un poco entenderlo:
Tanto el Service Router como el Distributed Router existen dentro de los logical routers (T1 y T0)
Es decir, en un Logical Router T0 vamos a tener un componente del Distributed Router y un Componente del Service Router:
– El distributed router vive en el kernel de todos los hipervisores (al igual que el DLR)
– El service router vive en los edge nodes (debido a que hay servicios Norte-Sur que no son distribuidos, por ejemplo: NAT)
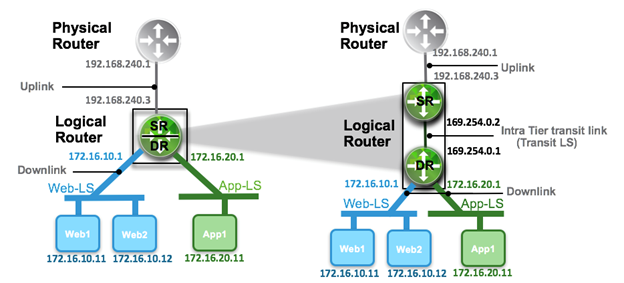
Adicionalmente, los Logical router Tier-0 corren sobre los recuirsos del Edge Cluster.
Plano de datos – NSX Edge
Ahora cada vez que creas un NSX Edge, vas a necesitar un NSX Edge cluster, como decíamos antes los Logical Router Tier-0 corren en los recursos del Edge Cluster, por más que tengas un solo NSX Edge, necesitas crear un Edge Cluster.
Otro cambio importante a nivel NSX Edge es que ahora podemos instalarlo sobre servidores bare metal y no solo como VMs. Esto es sumamente interesante si tenemos en cuenta el partnership de VMware con Nvidia, Project monterey y el avance de ESXi on ARM, ¿Te imaginas corriendo un NSX edge en un raspberry pi?, no es algo tan lejano.

Seguridad
Algunas de las mejoras a nivel seguridad.
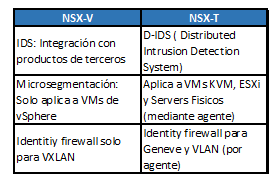
Cabe aclarar que el identity firewall solo funciona con VMs windows que tengan active directory (Windows 10 y Windows 2019 están soportados)
Migración
De momento exiten dos modos de migración:
Migración en paralelo: en otras palabras significa tener NSX-V y NSX-T en paralelo, esta opción está buena si aprovechamos un recambio de hardware o un upgrade de versión.
La migración In place sirve para entornos que es dificil el recambio, esto es un estilo Lift and Shift.

VMware recomienda contactar a PSO para revisar los pasos previos a la migración.
Conclusión
Por más que NSX for vSphere es un producto super robusto, está limitado al SDDC de VMware vSphere.
NSX-T es un producto concebido para el Multi-Cloud, teniendo en cuenta productos Cloud Native como Kubernetes.
Como se prevee que para 2025 el 60% de las empresas van a tener sus Workloads en la nube, sería una buena idea empezar a considerar NSX-T para llegar al Multi-Cloud
Espero que te haya servido, por favor comentame que te pareció.
Saludos
N.