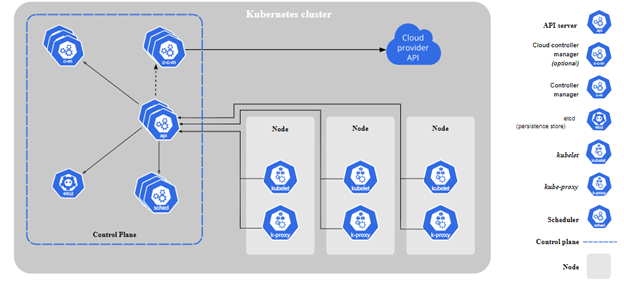
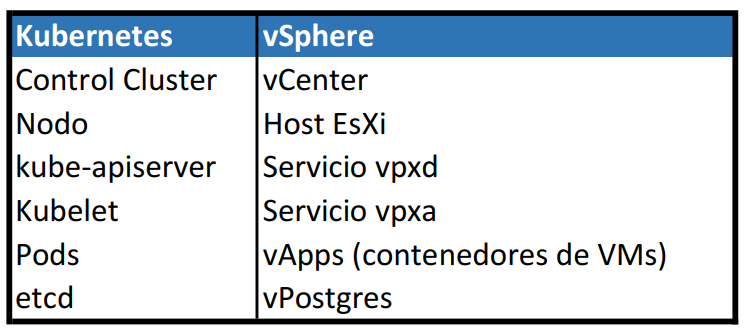
VMware Explore Las Vegas is around the corner, it will take place on August 21st to 24th in the Venetian convention center.
I think it’s an excellent opportunity for all the IT professionals that have the opportunity to assist and see what VMware has prepared for us.
Here are top 5 sessions I’m looking forward to:
Accelerate Digital, Customer-Centric Banking – A Financial Service Workshop [INDT2712LV]
As a financial services IT leader, you strive to deliver exceptional customer experiences while investing in modernization strategies that fuel growth, innovation and efficiencies. In this interactive financial services workshop, learn how IT leaders like you deliver customer-centric digital banking experiences. Industry leaders will discuss the trends, best practices, and lessons learned as they accelerate digital transformation. In panel discussions and interviews, hear from financial services leaders. From infrastructure modernization to building modern apps, learn practical ways to accelerate the delivery of new products, services and capabilities that improve customer experience and boost competitive advantage. You will also have the chance to participate in a Q&A with the customer panelists and VMware industry experts.
Speakers:
Steven Fusco, Global Business Solutions Strategist, VMware
Joe Chenevey, Principal Solutions Architect, VMware
Paul Nothard, Global Financial Services Industry Group, VMware
Track: Cloud & Edge Infrastructure
Session Type: Tutorial
Level: Business 100
Primary Product: VMware Cloud
Products: VMware NSX, VMware Tanzu, VMware Workspace ONE, VMware Cloud, VMware Aria Automation
Primary Session Audience: VP, Cloud
Session Audience: CIO, VP, Apps & Platforms, VP, End User Computing, VP, Infrastructure & Operations, VP, Cloud
Why am I interested in this session?
For the past years I’ve been heavily involved in the financial sector and I think it’s a business that is in constant change.
When my parents needed to make a deposit, they needed to go to the bank with the cash and make the deposit, the same thing if they applied for a loan or a credit card.
I manage all my banking through the comfort of my phone and I don’t even know which is my bank’s office.
I think it’s important to understand what are the trends in the fintech industry, how VMware is helping, and how we as IT professionals can prepare ourselves for the upcoming days.
60 Minutes of NUMA – A CPU is not a CPU anymore [CODEB2761LV]
Recently both AMD and Intel made their flagship Server CPUs available, the AMD EPYC and the 4th generation of the Intel Xeon Scalable Processor. Both follow a similar paradigm of the multi-chip, multi-tile module design, impacting kernel scheduling and workload sizing to work around the application expectation of a CPU subsystem. Besides the traditional deep dive of NUMA scheduling, we will discuss the new vSphere 8 functionality solving the age-old question, how many cores per socket? We will show real-life data on NUMA-locality’s importance for a Machine Learning\HPC application that runs on GPUs. We will look at the latest CPU architecture developments, such as the Sapphire Rapids’ new onboard accelerators, which can help you guide your data center hardware refresh. Join me as we dive into this exciting and critically important space.
Speaker: Frank Denneman, Chief Technologist, VMware
Track: Cloud & Edge Infrastructure
Session Type: Breakout Session
Level: Technical 300
Primary Product: VMware vSphere
Products: VMware Tanzu, VMware vSphere, VMware vSphere with VMware Tanzu
Primary Session Audience: Infrastructure Architect
Session Audience: Cloud Admin, Enterprise Architect, Infrastructure Architect, SysAdmin, Platform Ops
Why am I interested in this session?
I’ve been reading Frank’s vSphere Resource Deep Dives for the past years and I think it’s a very good way to understand how vSphere (or vSAN) works under the hood (not only what happens when you click X or Y). In VMworld 2020 I attended this session and I feel it upscaled my understanding of ESXi and vCenter to new levels, being able to provide performance fine-tuning recommendations to my customers in the best way possible.
Am I Being Phished? – Protect Your Mobile Users with Workspace ONE Mobile Threat Defense [EUSB2727LV]
The use of mobile devices in enterprises increases and is a key satisfaction metric from employees who work from anywhere. But the number of threats impacting mobile users increases in number and complexity. How can you protect your mobile users from new threats, such as phishing, that arise in all sorts of applications while still protecting their privacy? Learn how to configure and deploy VMware Workspace ONE Mobile Threat Defense to protect your organization as an integration into your Workspace ONE environment.
Speaker: Andreano Lanusse, Staff EUC Architect, VMware
Track: Hybrid Workforce
Session Type: Breakout Session
Level: Technical 200
Primary Product: VMware Workspace ONE Mobile Threat Defense
Products: VMware Workspace ONE Intelligence, VMware Workspace ONE UEM, VMware Workspace ONE Mobile Threat Defense
Primary Session Audience: VP, End User Computing
Session Audience: VP, End User Computing, Senior Security Manager, EUC Specialist
Why am I interested in this session?
Recently I’ve been working a lot with workspace one, and I think it’s a great product (not a magic product as many people think) and corporate mobile phones are often a neglected part of enterprise security.
I think this session will help me understand Workspace One MTD, a fairly recent product, and how can it help secure the mobile fleet of my clients.
A Decade of Platform Engineering with VMware Tanzu [MAPB2122LV]
Kubernetes has become the de facto standard for container orchestration. Platform engineering teams have options when using that technology, such as a prescriptive approach with platform as a service or a more flexible approach where they can customize their Kubernetes platform. VMware Tanzu supports multiple containerization journeys with many ways of running applications. Platform teams can choose between VMware Tanzu Application Service or VMware Tanzu for Kubernetes Operations. This panel, which includes Tanzu Vanguards, will share important considerations when running the platform, including security, survivability, scale, cloud native secrets, networking do’s and don’ts, ChatOps, and more. This panel will also share lessons learned and best practices for dealing with chatty neighbors and microservices, using isolation segments for specific use cases, and application and platform monitoring.
Speakers:
Nick Kuhn, Senior Technical Marketing Architect, VMware
Pawel Piotrowski, Architect, S&T Poland
Jonathan Regehr, Platform Architect, Garmin International
Venkat Jagana, Vice President&Distinguished Engineer, Kyndryl
Kerry Schaffer, Senior IT Director, OneMagnify
Track: Modern Applications & Cloud Management
Session Type: Breakout Session
Level: Technical 300
Primary Product: VMware Tanzu Application Service
Products: VMware Tanzu Application Platform, VMware Tanzu for Kubernetes Operations, VMware Tanzu Application Service
Primary Session Audience: Platform Ops
Session Audience: VP, Apps & Platforms, Application Developer, Cloud Architect, DevOps Manager, Platform Ops
Why am I interested in this session?
I’ve been working with Tanzu a lot recently, and although I think it’s a great product. I feel Kubernetes in general is complex to operate (Day 2 Operations), and it’s a shared feeling with some peers. I have the impression that this session, in collaboration with Tanzu Vanguard Experts will provide me with insights or ideas to apply in our environment.
Machine Learning Accelerator Deep Dive [CEIM1849LV]
In this Meet the Expert session, you can ask all your questions about deploying machine learning workload and the challenges around accelerators. When do I use CPU resources, what about NUMA relation, when do I use passthrough, and what benefit has NVIDIA AI Enterprise? What’s the difference between MIG and time-sliced, and how can I avoid cluster defragmentation in certain scenarios? Join me as we dive into this exciting and critically important space.
Speaker: Frank Denneman, Chief Technologist, VMware
Track: Cloud & Edge Infrastructure
Session Type: Meet the Expert Roundtable
Level: Technical 300
Primary Product: VMware vSphere
Products: VMware Tanzu, VMware vSphere, VMware Edge, VMware Cloud, VMware + NVIDIA AI-Ready Enterprise Platform
Primary Session Audience: Enterprise Architect
Session Audience: Enterprise Architect, Infrastructure Architect, SysAdmin, Platform Ops
Why am I interested in this session?
AI Is the new shiny thing, In a couple of months it generated more value-added than Web3 (Sorry Crypto Bro). My perspective is that in the upcoming years, we will start seeing more and more ML workloads in the enterprise data center so I would like to understand how to fine-tune the performance and understand the challenges and limitations of running ML workloads on vSphere clusters.
And why not, if Machines Enslave humanity, be a survivor just because I know how to feed them more servers?
Bonus Track: Lessons Learned from the Most Complex VMware Aria Automation 7 to 8 Migration to Date [CEIB1318LV]
In this session, learn and understand everything that happened under the hood in VMware’s most complex migration to date of VMware Aria Automation (formerly VMware vRealize Automation) version 7 to 8, involving an industry-leading transportation customer. Find out how we were able to solve their unique use case and, through careful thinking and thousands of lines of code, get them to the finish line.
Speakers:
Pontus Rydin, Principal Systems Engineer, VMware
Lucho Delorenzi, Staff Customer Success Architect, VMware
Track: Modern Applications & Cloud Management
Session Type: Breakout Session
Level: Technical 300
Primary Product: VMware Aria Automation
Products: VMware NSX, VMware Aria Automation, VMware Aria Automation Orchestrator
Primary Session Audience: Cloud Architect
Session Audience: Cloud Admin, Cloud Architect, Infrastructure Architect, Platform Ops, VP, Cloud
Why am I interested in this session?
Aria automation (sorry, but in my twisted mind I still call it, vRealize Automation) is one of the most powerful products for the SDDC and the multi-cloud environment, that being said, it’s also one of the most complex.
My friend and colleague Lucho is delivering this session and based on all the sessions he provided to VMUG Argentina I think we can all learn a thing or two from him.