Esta semana fue la edición 2020 del VMworld y hubo una palabra que se repitió más que nada: Kubernetes. El año pasado VMware compró Pivotal y a los pocos días anunciaron, Project Pacific, su re-ingeniería de la plataforma.
Este año tuve la suerte de hacer cursos de vRealize Automation 8 y algo que me llamó la atención es que lo que antes eran servicios, ahora se maneja con pods dentro de los appliances.
Cómo hasta ese entonces no había visto mucho de Kubernetes, más que alguna charla y o algo en la facu, me decidí a investigar y “enseñarme” cómo funcionan.
Me gustaría compartirles este glosario con una descripción para que todos puedan entender que es este servicio que llegó para quedarse.
Al final del post, comparto algunos recursos que me sirvieron para aprender y son 100% gratuitos.
¿Qué es Kubernetes?
Kubernetes es una plataforma Open-Source para administrar y orquestar containers que facilita la configuración declarativa y la automatización.
¿Quién desarrolla Kubernetes?
Kubernetes comenzó como un proyecto de Google y lo hicieron Open-Source en 2014, actualmente lo mantiene Cloud Native Foundation y los mayores vendors de tecnología tienen sus implementaciones. Por ejemplo RedHat con Openshift o VMware con Tanzu, entre otros.
Kubernetes en griego significa timonel, por eso el logo es un timón.
¿Por qué Implementar Kubernetes?
Para responder esta pregunta hay que ir un par de años atrás en el datacenter y entender cuáles son las problemáticas que viene a resolver.
Si nos fijamos en la primera etapa: todos los servidores eran físicos (bare metal), es decir, por cada aplicación que manteníamos necesitábamos tener un servidor con sus recursos (CPU/Memoria/NIC’s/Storage), un sistema operativo y sus aplicaciones:
Este modelo aumentaba los costos de hardware, mantenimiento y era poco resiliente a fallas.
Sumado a esto, la instalación y configuración de servidores bare-metal era (y sigue siendo) un proceso tedioso y lento.
Para resolver ese problema llegó la virtualización:
La virtualización permite colocar múltiples máquinas virtuales (VMs) en un solo servidor físico (Hipervisor) esto permite consolidar recursos (CPU, Memoria, Storage) , acelerar tiempos de aprovisionamiento y da un mayor nivel de seguridad ya que una VM no puede acceder a los recursos de otra VM. Cada VM tiene su propio sistema operativo y aplicaciones.
Containers:
Los containers son parecidos a las máquinas virtuales, pero tienen aislamiento flexible, por lo que comparten el sistema operativo entre distintas Apps. Al igual que las VMs los containers tienen su propio CPU, Memoria, tiempo de procesamiento y demás, pero no dependen de la infraestructura, por lo que son portables.
Adicionalmente, dentro de cada container están resueltas todas las dependencias de una aplicación: es decir si yo necesito instalar LAMP debería tener alguna versión de Linux, Apache, MySQL y PHP.
El container se va a asegurar de que las versiones de Apache, MySQL y PHP sea la misma en cualquier lugar que corra el container. Lo que garantiza la portabilidad.
Por último, los containers fueron concebidos con la agilidad en mente, por lo que la automatización es 100% compatible.
Otra cosa importante, como las Máquinas virtuales tienen el hipervisor los containers tienen el Container Engine. En este caso vamos a hablar de Docker.
En este video dan una explicación muy buena del porqué del nombre containers.
Ahora sí, ¿por qué Kubernetes?
Es sabido que todos los servidores pueden fallar, y nuestro trabajo como profesionales de IT es evitar que fallen. Kubernetes está pensado desde esa premisa, sabiendo que nuestros servicios van a fallar, nos da la posibilidad de controlar el cómo se va a comportar nuestra infraestructura cuando fallen.
– Balanceo de Cargas nativo: Podemos exponer un container por IP de servicio o DNS. Si el trafico es alto Kubernetes permite balancear la carga.
– Orquestación de storage: Permite automatizar la provisión de storage a tus containers.
– Rollouts y Rollbacks automáticos: Permite definir manifiestos YAML con el estado deseado de nuestros containers.
– Self Healing: Kubernetes reinicia, reemplaza y mata containers en base a su estado.
Kubernetes es la clave para dejar de tratar a nuestros servidores como Mascotas y empezar a tratarlos como ganado.
¿Cómo funciona Kubernetes?
Cuando implementas Kubernetes tenés un cluster.
El cluster es un conjunto de máquinas workers, o nodos, que va a correr nuestros containers, todos los clusters tienen al menos un nodo. En Kubernetes los nodos ejecutan Pods (que sería un container de containers)
La implementación también tiene un plano de control que supervisa y administra los nodos y los pods.
En entornos productivos, el control cluster tiene varias máquinas master y también múltiples nodos para aumentar la resiliencia del cluster.
Acá dejo un diagrama
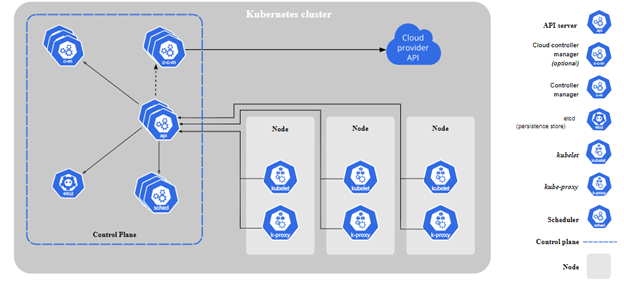
Veamos que hace cada componente:
Componentes del Control plane:
Los componentes del control plane toman decisiones sobre los demás nodos de Kubernetes.
Por Ejemplo: definir donde va a correr cada Pod, validar si hay que agregar más replicas, etc.
Estos componentes se instalan en la misma máquina por lo general, y se pueden usar clusters distribuidos como dijimos antes. En estos servidores no se ejecutan containers de usuario.
kube-apiserver:Se encarga de exponer la API de Kubernetes, el frontend del control plane de Kubernetes. Todas las interacciones que tengamos con nuestro cluster de Kubernetes van a ser mediante esta api.
etcd:Es la base de datos del cluster de Kubernetes.
kube-scheduler: Indica en que nodo se van a crear los pods.kube-controller-manager:
Unifica y administra los procesos del cluster de control.
Algunos procesos que administra son:
Node controller: Monitorea el estado de los nodes y notifica si alguno se cae.
Replication Controller: Es el encargado de monitorear y aplicar la cantidad de replicas correctas para cada pod.cloud-controller-manager: Te permite conectar tu cluster a un proveedor de servicios en la nube (Google Cloud, Amazon, Azure, etc) y separa los componetnes que interactúan con la nube de los que solo interactúan de forma local. Este componente solo existe en la nube, si tenés un entorno on-premise no lo vas a ver.
Componentes de los nodos:
Nota: los nodos tienen que correr sobre alguna distribución de Linux.
Container Engine: El software que se encarga de correr containers, por ejemplo Docker, containerd, podman, etc. kubelet: Es un agente que corre en cada nodo del cluster y se asegura que los containers estén corriendo en un pod. Está hablando constantemente con el kube-apiserver para validar que los pods y servicios cumplan con el estado deseado. Adicionalmente ejecuta las acciones que le pasa el apiserver.kube-proxy: es un proxy de red que corre en cada nodo.
Se encarga de mantener las reglas de red en cada nodo. Esas reglas permiten que los pods puedan tener conectividad fuera del nodo.Pods: es un grupo de uno o más containers, como me explico mi queridísimo Guille Deprati, es un container de containers.
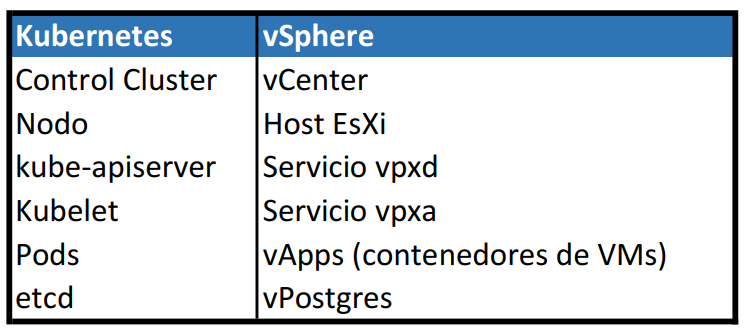
Algo que a mi me sirvió mucho para entender la arquitectura de Kubernetes es compararlo con lo que entiendo y conozco. Cómo soy administrador VMware me sirve hacer la equivalencia entre Kubernetes y vSphere.
Otro recurso importante es el Container Registry:
Basicamente es un repositorio de imagenes de containers (container images) a partir de las cuales vamos a crear nuestras pods.
Existen los Registros Públicos como ser Docker Hub y podemos tener registros privados dentro de nuestra organización (Red Hat Quay, Harbor, etc). Los cloud providers (AWS, Azure, Google Cloud, Alibaba) probeen su servicio de container registry.
Recursos de estudio:
Los recursos que usé durante estos meses fueron los siguientes:
- Kube Academy
- Kubernetes.io
- Edx – Introduction to Kubernetes
- Coursera – Google Cloud Engine offering
Estos son pagos, pero los conseguí gratis por una beca del GCBA. - VMware Cloud Native Apps – You Tube
Espero que te haya servido el post, por favor comentame si te gustó o que se puede mejorar.
Saludos