Hace algunos meses que estoy entrando día a día a VMTN (VMware Communities) y veo que muchas de las preguntas son del índole de ¿Puedo instalar ESXi en X hardware? o Instalé vCenter y no anda como espero.
Muchos de esos posteos son de usuarios que están probando vSphere por primera vez o de gente que no es nativa de la virtualización, no obstante, este post tiene como objetivo ayudar a todos los que están dando sus pasos en el mundo de la virtualización.
Diseño
La parte más importante de cualquier proyecto, en cualquier rubro, es el planeamiento.
Cuanto más tiempo pongamos planeando las cosas menos vamos a tener que poner arreglando problemas derivados de diseños fallidos.
Te dejo algunas preguntas que podes hacerte a la hora de empezar un proyecto de vSphere.
Análisis inicial
¿Para que quiero hacer esta implementación? Puede ser que quiera hacer un recambio de hardware por obsolescencia, puede ser que quiera desarrollar un proyecto de Hybrid Cloud o algo similar.
De este análisis inicial van a salir los requerimientos iniciales del proyecto, por ejemplo:
¿Cuántas VMs vamos a alocar en nuestros clusters?
¿Qué máquinas van a correr en mis clusters? No es lo mismo a nivel recursos correr un cluster de VDI que un cluster de Kubernetes o una base de datos Oracle.
¿Cuántos datos podemos ubicar en nuestro storage?
¿Puedo aceptar contención de recursos?
¿Cuánto voy a crecer por año?
¿Necesito un solo sitio? ¿Necesito más de un sitio?
Hardware
Un proyecto de virtualización depende del hardware que se use, algunas de las preguntas que podemos hacernos antes de adquirir el hardware son:
¿Qué tipo de servidores vamos a usar? (Blades/Rackeables/HCI) ¿Vamos a adquirir hardware nuevo? ¿Vamos a actualizar el hardware existente?
¿Cuántos CPU’s necesitamos? ¿Qué procesadores vamos a usar? ¿Cuántos cores voy a tener?
Estas primeras preguntas van a ser clave. Tené en cuenta que dentro de un mismo cluster lo ideal es tener hosts de la misma versión de ESXi y que los procesadores sean de la misma marca y familia (por EVC)
¿Cuánta memoria necesitamos?
¿Cuántas NICs necesito? ¿Cuántas HBA? Como mínimo siempre 2 para tener redundancia
¿Qué versión de vSphere voy a implementar?
¿Necesitamos algún tipo de hardware especial? (Placas de video, Hard Tokens, etc)
¿Tengo lugar en el datacenter? ¿Tengo suficiente capacidad en los racks? ¿Me alcanza la capacidad de computo? ¿Tengo puertos libres en los switches?
¿Dónde voy a instalar mi host? (Disco Local, SATADOM, SD, etc )
¿Voy a armar RAID para los discos locales? ¿Qué RAID?
Algo que me parece super importante aclarar, no podemos ir a instalar ningún servidor sin antes haber chequeado la matriz de compatibilidad (más ahora, ya que vSpher 7 no usa más los drivers VMKlinux como en versiones anteriores). Si nuestro proyecto usa vSAN podemos chequear la matriz de compatibilidad de vSAN o usar hardware vSAN ready.
Storage
¿Qué tipo de storage vamos a usar? (SAN/iSCSI/vSAN/NFS)
¿Vamos a adquirir hardware dedicado o tenemos que usar el hardware existente?
Cada tipo de storage tiene sus ventajas y sus limitaciones, por ejemplo, el storage SAN suele sumar complejidad a la administración (Zoning), mientras que iSCSI es más sencillo.
SAN tiene una red dedicada (con su propio protocolo) mientras que vSAN, iSCSI y NFS usan la red LAN. Por consiguiente, sumando tráfico a las NICs del servidor.
¿Necesito una solución metro?
¿Tengo suficientes puertos de SAN disponibles? (si es que los uso)
Networking
Algunas de las preguntas importantes a nivel redes
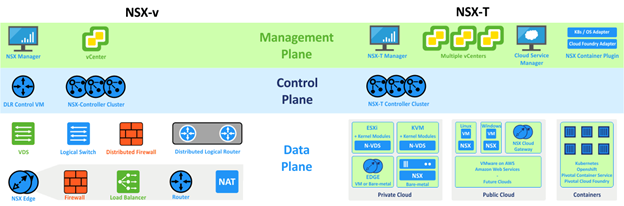
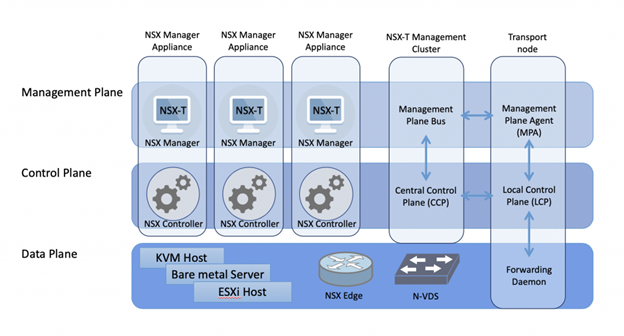
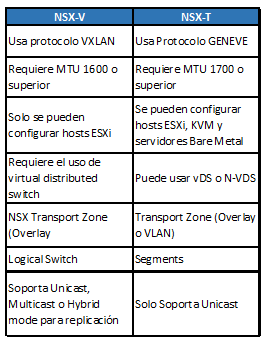
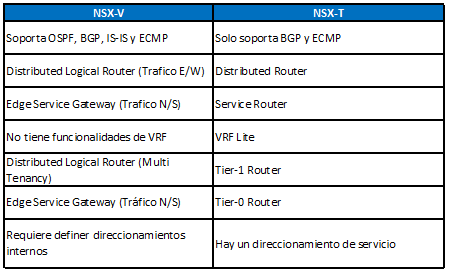
¿Voy a usar NSX?
¿Cuál es el troughput de mis equipos?
¿Cuántas VLANs administro?
¿Cómo está configurado MTU?
¿Tengo configurado CDP o LLDP?
¿Voy a usar algún mecanismo para prevenir loops (STP)?
¿Tengo suficientes puertos disponibles en los switches de red?
Estas respuestas nos van a decir como tenemos que configurar nuestros switches de vSphere.
vSphere
¿Qué servicios voy a necesitar? ¿Voy a tener solo ESXi? ¿Voy a tener vCenter? ¿vSAN? ¿vROPs?
¿Necesito más de un vCenter?
¿Necesito priorizar la disponibilidad?
¿Mis aplicaciones pueden tolerar un reinicio o no es aceptable?
¿Cuántos hosts caídos puedo tolerar?
¿Cómo van a bootear mis hosts? (Stateless vs Stateful)
Esta información te va a ayudar a determinar, entre otras cosas, cual es la licencia que necesitas.
Estas son algunas (porque siempre hay más) de las preguntas que tenemos que hacernos para empezar a diseñar una solución de vSphere que sea de calidad y resiliente a fallos.
A la hora de la implementación yo tengo este checklist para validar que todo esté listo para instalar y evitar perdidas de tiempo.
Una aclaración importante: Que algo no esté soportado en la matriz de comptabilidad significa que VMware no te va a aceptar los casos de soporte, no que no va a funcionar.
Por ejemplo, correr ESXi en modo nested no está soportado y se recomienda no correr VMs productivas, pero si lo usas para laboratorios está perfecto.
Espero te haya servido
Saludos
Nacho